Stata 简介
这份讲义旨在介绍 Stata 的界面、主要功能,以及使用 Stata 进行实证分析的工作流程。
我一直秉承「干中学」的理念。因此,在阅读这份讲义时,我强烈建议大家不时停下来,在 Stata 中亲自操作一下。将重点内容记录下来,并形成两份笔记:一份是包含关键 Stata 代码的 dofile,以便日后查阅和调用;另一份是 Markdown 笔记,内含每个知识点的相关链接和参考资料,以及你对关键命令和代码的解释。
0. Stata 概览
0.0 实证分析的流程
- [1] 一个想法:研究假设
- [2] 模型设定
- [3] 变量界定
- [4] 收集数据、数据清洗、生成变量
- [5] 统计和回归分析
- 支持 → [6]
- 不支持 → [1]-[5]
- [6] 解释结果、结论
:dog: 讨论:在上述过程中,Stata 的角色和作用是什么?
0.1 Stata 工作流程
图 图 1 呈现了 Stata 的接本工作流程。

0.2 Stata 基本语法格式
在 Stata 命令窗口中输入 help language 命令,可以查看其基本语法规则。
[U] 11 Language syntax ← Stata 的基本语法格式都在这里

0.3 Stata 学习资源
- 连玉君, Stata 33 讲:b 站视频, 课件
- 连玉君老师经验分享:一个资深 Stata 用户的若干思考 -
- DATA ANALYSIS NOTES: LINKS AND GENERAL GUIDELINES
- Internet Guide to Stata
- SSCC 在线课程
- GitHub
- 提供了大量用 Stata 完成的项目的完整数据和 dofile 等。
- 可以在 github.com, 中搜索
stata。 - 点击
fork按钮,克隆之 → Clone 到国内 码云 (gitee.com) 账户
0.4 Stata 用户指南:最好的入门资料
- 务必通读 [U] User Guide (PDF)

0.5 Stata 命令概览
Stata 各类方法和模型汇总 → stata.com/features
- Linear models
- regression • censored outcomes • endogenous regressors • bootstrap, jackknife, and robust and cluster–robust variance • instrumental variables • quantile regression • GLS • DID • more
- Panel/longitudinal data
- RE and FE • linear mixed models • RE probit • GEE • RE/FE Poisson • dynamic panel-data models • IV • DID • panel unit-root tests • more
- Binary, count, and limited outcomes
- logit, probit, tobit • Poisson • nbreg • conditional, multinomial, nested, ordered, Logit • mprobit • zero-inflated and left-truncated models • selection models • marginal effects • more
- Choice models | Extended regression models (ERMs) | Generalized linear models (GLMs)
- Spatial autoregressive models | DSGE models | Tests, predictions, and effects
- Contrasts, pairwise comparisons, and margins | Resampling and simulation methods
0.6 Stata 帮助和搜索功能:help 和 search
help regress// [R] help | 完整攻略- 适用:想要了解某个具体命令的使用细节
ihelp regress:外部命令ihelp可以快速打开 PDF 版本的帮助文档
search panel data// [R] search
findit dynamic threshold// 旧版命令search Lian Yujun// 搜索人名- 搜索建议:
help searchadvice
. search dynamic panel data

0.7 推文 · 数据 · 代码:lianxh 和 songbl
安装
. ssc install lianxh
. ssc install songbl使用:
. lianxh
. lianxh DID
. songbl
. songbl 静态面板
0.8 Stata 功能概览
Note:点击蓝色链接可以直接打开对应的 PDF 手册,查看命令清单
help language// [U] 11 Language syntax ← Stata 的基本语法格式都在这里help data_management// [D] data_managementhelp program// [P] program → [U] 18 Programming Statahelp graph// [G-2] graphhelp graph intro// [G-1] graph intro,图形编辑器
help estcom// 统计和回归分析
0.9 你必须掌握的一些 Stata 命令
:apple: PDF:[U] 28 Commands everyone should know
- Getting help
help, search,ssc install,net installlianxh
- Keeping Stata up to date
ado, net, update, ado update
- Operating system interface
pwd, cd, dir, sysdir, adopath, shellout
- Using and saving data from disk
use, save, sysuse, webuse, bcuse
- Inputting data into Stata
import excel, insheet, edit
- Basic data reporting
describe, des2, codebook, frelist, browse, count, inspecttable, tabulate, summarize, fsum
- Data manipulation
clearappend, merge, reshapegenerate, replace, egen, drop, keep, renamesort, gsort, orderencode, decodeby, bysortframes
- Graphing data
twoway scatter / linehistogram, kdensity, graph bargraph export
- Convenience
display, cls
1. Stata 主界面
对于新手来讲,请务必花点时间全面了解一下 Stata 的用户界面,以便了解 Stata 的主要功能,这对于有效地使用Stata进行数据分析至关重要。详情参见 Stata user interface。
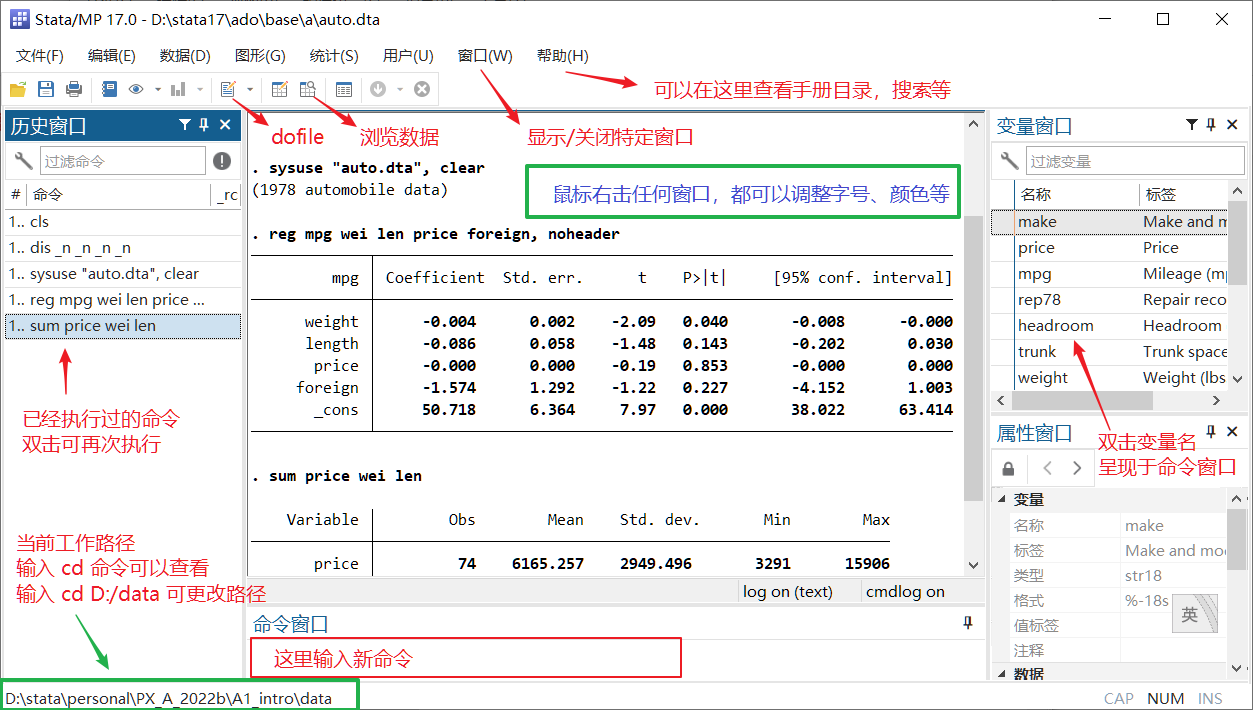
1.1 窗口布局及小技巧
默认情况下,Stata 的主界面会显示以下五个窗口:
- 结果窗口:正中间面积最大的窗口,用于展示分析结果。
- 右击后选择「首选项 (P)」,即可设定窗口的配色、字体大小等外观参数。
- 命令窗口:在此可临时输入简短命令,如
help regress、findit winsor、ssc hot、adopath、lianxh DID等。- 按 Esc 键可清空命令窗口中的全部内容。
- 按 PgUp / PgDn 键可翻看此前执行过的命令。
- 输入变量名首字母后按 Tab 键,可自动补全变量名或显示备选变量列表。
- 输入
cls并回车,可一键清空结果窗口。
- 历史窗口 (Review Window):列示此前执行过的所有命令。
- 单击某条命令,则其会显示在命令窗口中,便于修改与检查。
- 双击某条命令,则立即再次执行该指令。
- 变量窗口:列出当前数据集中的所有变量及其标签信息。
- 双击某个变量名,即可将该变量名直接插入至命令窗口中,减少手动输入量。
- 属性窗口:显示所选变量或数据集的详细信息,包括数据类型、格式、值标签、注释以及存储类型等。这有助于你快速了解并管理变量的属性。
小技巧 (Tips):
- 窗口布局(适合有一定使用经验的用户):
- 如果你偏好「一边执行命令,一边查看结果」的简洁工作环境,可只保留 结果窗口 和 命令窗口,同时将 dofile 编辑器 调整至屏幕半侧大小,方便同时查看代码和结果。
- 如需恢复先前关闭的窗口,只需从主菜单中选择「窗口」进行还原。
- 窗口属性设置(适用于大多数窗口):
- 在窗口空白处右击,可设定字体、字号、配色等界面参数。
- 按 PgUp / PgDn 键可以翻页浏览内容。
极简版窗口布局
我平时关闭主界面中的多余窗口,仅保留 命令窗口 和 结果窗口;同时,我会把 dofile 编辑器设定为屏幕宽度的一半。这样,我就可以在右侧的 dofile 中执行命令,在左侧的结果窗口中查看结果。需要切换窗口时,可以使用快捷键 Alt + Tab。当然,如果你是两个显示器双屏显示,那就更方便了。
若需恢复已经关闭的窗口,可以点击 窗口 (W) 菜单进行设置。

图 2:简洁版 Stata 界面
1.2 主菜单

- 顶部和底部
- 顶部:显示了 Stata 版本和当前内存中已经读入的数据集
- 底部:左下角显示了当前的工作路径。若执行
dir,use等命令,默认是浏览或调用该文件夹下的文件。
- 主菜单:
- 文件 (F):打开/保存文件、导入/导出数据、打开示例数据集、管理项目文件
- 编辑 (E):复制、粘贴、查找/替换文本、清除结果窗口、用户偏好设定
- 数据 (D):浏览/编辑数据、创建或修改变量、对数据进行排序、合并拆分数据集、设定变量标签和数值标签
- 统计 (S):运行回归、检验、面板数据分析、时间序列分析、计量经济学模型估计、非参数统计等各种统计分析方法
- 图形 (G):绘制散点图、柱状图、线形图、箱线图等图形,定制图表外观与格式
- 用户 (U):加载用户编写的程序扩展、插件、脚本文件等 (很少用)
- 窗口 (W):在命令窗口、历史命令窗口、变量窗口等界面元素之间切换与管理
- 可以临时关闭 / 开启特定窗口
- 帮助 (H):访问 Stata 帮助文档、检索命令手册、查看更新日志、联系技术支持
建议新用户依次点击上述菜单,以便快速了解 Stata 的主要功能。
1.3 按钮条 (图标)
主菜单下方有一行图标,是一些常用功能的直达通道:

 :日志文件 [GSW] 16 Saving and printing results by using logs files
:日志文件 [GSW] 16 Saving and printing results by using logs files :图形浏览器,点击下拉按钮可以选择需要浏览的图片 [GSW] 14 Graphing data
:图形浏览器,点击下拉按钮可以选择需要浏览的图片 [GSW] 14 Graphing data :dofile 编辑器 [GSW] 13 Using the Do-file Editor。点击打开一个新的 dofile 文档。
:dofile 编辑器 [GSW] 13 Using the Do-file Editor。点击打开一个新的 dofile 文档。 :数据编辑器 [GSW] 6 Using the Data Editor。点击查看内存中的数据表 (可编辑模式)。
:数据编辑器 [GSW] 6 Using the Data Editor。点击查看内存中的数据表 (可编辑模式)。 :数据浏览器。[GSW] 6 Using the Data Editor。点击浏览内存中的数据表 (无法编辑)。
:数据浏览器。[GSW] 6 Using the Data Editor。点击浏览内存中的数据表 (无法编辑)。 :强制中断当前运行的程序 (平时是灰色的
:强制中断当前运行的程序 (平时是灰色的  )。
)。
1.4 文件 (F) 菜单
文件 (F) 菜单主要涵盖如下功能:
- 打开数据文件
- 导入/导出数据
- 更改工作路径
- ……
- 全都可以用命令实现 (尽量用命令)
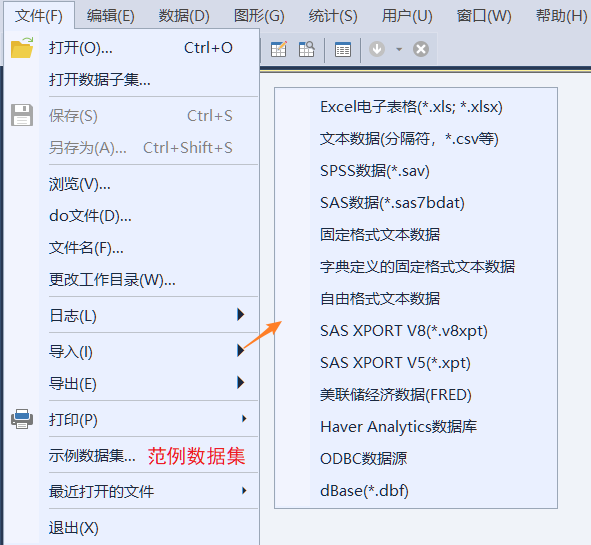
这里重点说明一下 导入 (I) 和 示例数据集 两个菜单:
- 导入 (I):支持多种数据格式的导入,如
.xlsx,.txt - 示例数据集:提供了一些可供演练的数据集,包括:
- Stata 自带的 26 个数据文件,这些文件都可以使用
sysuse命令调用,如sysuse auto.dta, clear; - Stata 手册中使用的各类范例数据文档清单,均可使用
webuse命令调用,如webuse nlswork.dta, clear。除了点击菜单,也可以使用如下命令查看上述数据文件列表:
help dta_examplels sysuse dir // 此处列出的数据文件都可以用 sysuse 命令调用 help dta_manuals - Stata 自带的 26 个数据文件,这些文件都可以使用
1.5 Edit (E) 菜单:界面风格
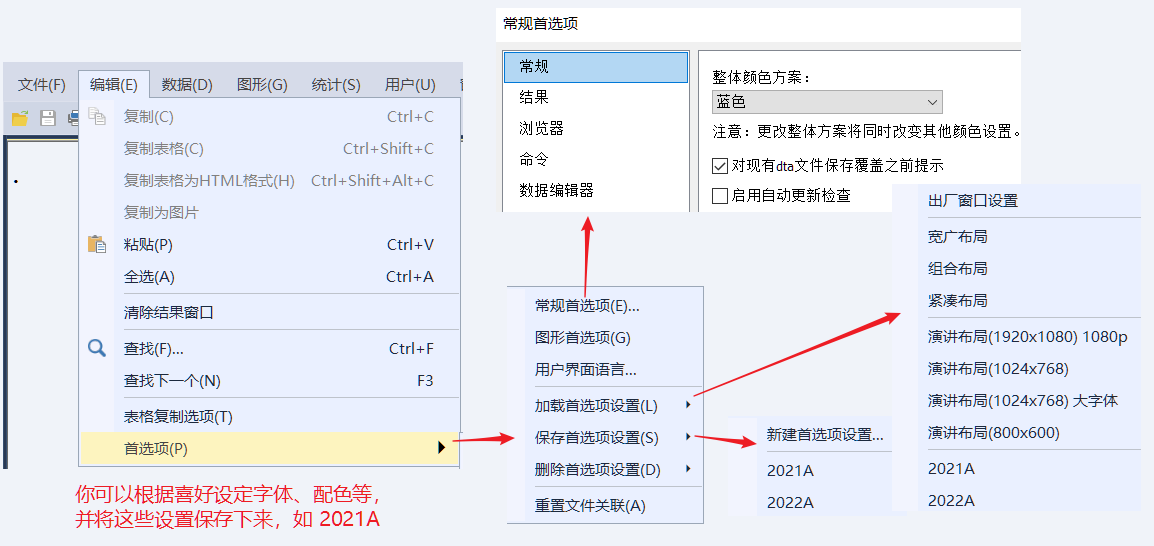
编辑菜单中的多数功能都一目了然,不再赘述。需要特别关注的是「首选项 (Preference)」子菜单。我们可以根据自己的喜好设定多种 Stata 界面的配色、字体等的风格,并将这些设定风格保存为模板,以便随后调用。
个性化设定
- 在 Stata 的任何一个窗口中都可以通过 右击鼠标 来设定
字体属性; - Stata 主界面设定:在 Stata 结果窗口中,右击鼠标 → Preference 可以进一步设定
结果窗口(Results)、文件浏览器(Viewer)、数据编辑器(Data Editor)等窗口的属性,主要涉及字体是否加粗、颜色、窗口背景色等。 - dofile 编辑器设定:打开 dofile 编辑器 (快捷键为:Ctrl+9,或者在命令窗口中输入
doedit),依次点击 Edit → Preferences,会弹出如下Do-file Editor Preferences→通用属性 (General)设定的对话框。详情参阅后文 dofile 编辑器 小节。 - 保存/更换模板:上述设定,都可以保存到一个模板中。Stata 支持多种模板,可以让你在早、中、晚使用不同的模板,既能调节心情,又能保护视力。
模板的使用
你可以根据不同场景的需要,设置不同的风格,并保存为多个模板,随后根据需要调用即可。
- 新建模板:编辑 (Edit) → 首选项 → 保存首选项设置 (S) → 新建首选项设置,自行定义模板名称,然后 确认 即可。
- 更换模板:编辑 (Edit) → 首选项 → 加载首选项设置 (L)
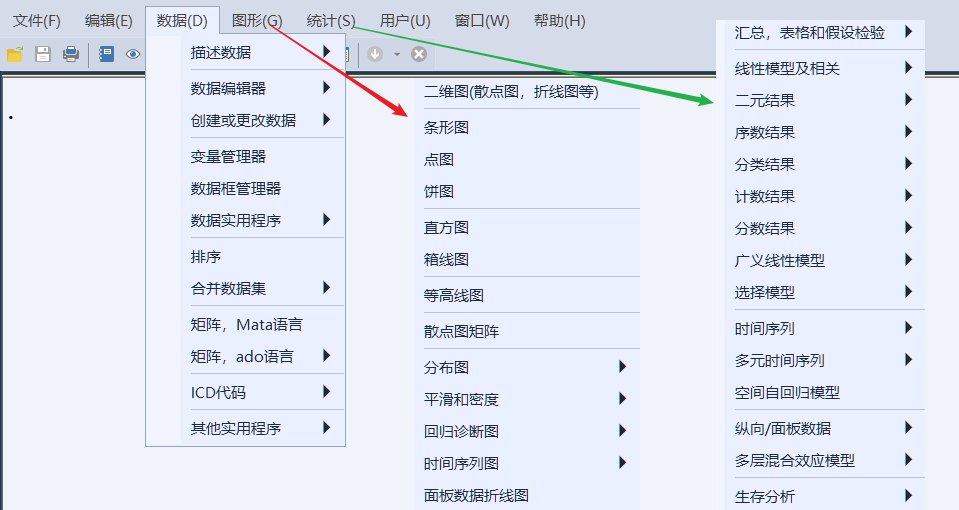
1.6 数据/图形/统计菜单
这三组菜单集合了 Stata 最主要的功能。菜单栏包括文件、编辑、数据、图形、统计、用户、窗口和帮助等功能。每个主菜单下都有多个子选项,提供各种数据管理和分析工具。
- 数据(D):涉及数据管理与分析,如数据汇总、描述性统计、线性模型、数据编辑器等。常用命令包括:
browse: 浏览数据表edit: 编辑数据表describe: 描述内存中的数据概况
- 图形(G):包含多种图表选项,如散点图、折线图、条形图、饼图、直方图、箱线图等。
- 统计(S):提供高级统计分析功能,如假设检验、广义线性模型、时间序列分析、生存分析等。
- 用户(U):可能包含用户设置或自定义选项,如界面布局的个性化设置。
- 窗口(W):管理打开的窗口,如排列或切换窗口,以便更有效地组织工作空间。
- 帮助(H):提供文档、教程和支持资源的访问,是一个全面的帮助系统。
此外,界面可能还包括工具栏,其中有常用功能的图标,如新建数据、打开文件、保存等。软件可能还具有数据编辑器或数据查看器,位于中心位置,配有输出、图表和脚本的面板或窗口。
2. Stata 工作流程
2.1 工作流程概览
Source: 连玉君, 陈鑫梅, 2020, 可重复性研究:如何保证你的研究结果可重现?, 连享会 No.124.
图 3 展示了一个典型的实证分析工作流程。你在本地或网盘中的文件夹中存如原始数据文件,然后在 Stata 中执行命令,以实现数据读入、清洗和分析,最后把结果输出成表格和图形,嵌入到 Word 或 TeX 文档中。
简言之,我们要实现「数据 → 代码 → 结果 → 文档」的有机衔接,让研究流程清晰透明,也方便日后重复或更新分析。

图 3:Stata 工作流程示意图
左:本地文件夹
本地文件夹:D:/paper/myAER,其中包含三个文件夹和一个 dofile:
- “./data0”:存放原始数据文件,如 data_org.xlsx
- “./dataClean”:存放清洗后的数据文件,如 data_clean.dta
- “./out”:存放输出结果,如回归表格 Table01.rtf 和图形 Fig01.png
dofile_myAER.do:Stata do 文档,记录所有处理过程。
采用这种分类管理方式,无论是查看数据源还是寻找输出文件,都能快速定位。与合作者分享论文复现资料时,也只需分享 dofile_myAER.do 和 “./data0” 子文件夹即可。合作者运行 dofile_myAER.do 后变会自动生成清洗后的数据文件和结果文档。
右:dofile
右上角打开的 dofile_myAER.do 是我们向 Stata 下达指令的脚本文件 (dofile)。具体解释如下:
- 首先,使用
global path "D:/paper/myAER"命令,指定了项目文件所在路径,并以此为基础定义了几个相对路径。在后续命令中,便可以使用$path,$data0等全局暂元来引用这些路径,而不必每次都手动输入完整路径。你的合作者只需酌情修改第 4 行的文件路径 (绝对路径),而无需做其他更改。 - 接下来,在
dofile中写好一系列命令,以便完成数据导入、清洗、回归以及结果输出等一整套流程。有了dofile,只需轻轻点一下执行按钮,就能让整套分析重复进行,也可以让修改和完善工作更有效率。 - dofile 中的第 15, 20 和 24 行都用于输出结果,分别将清洗后的中间数据,回归表格,以及生成的图形存储到项目文件夹 D:/paper/myAER 中的指定子文件中。随后你只需将这些表格和图形插入论文 Word 文档中即可。
中:Stata 主界面
在 Stata 的主界面中会呈现回归结果、显示输出的图片等。比如,
- 执行
reg price wei mpg, robust命令后,可以在 Stata 的结果窗口查看回归结果 - 进一步执行
esttab using "$path/out/Table01.rtf", replace命令时,结果窗口中会显示自动输出的 .rtf 文档 (等同于 word 文档) 的存储路径 (单击蓝色链接可以打开此文档)。 - 执行第 22-23 行的命令后,就会绘制散点图,并将图片以 .png 格式存储到
$out文件夹中。
小结
总之,dofile 就像一个中心控制台:我们在 dofile 中下达命令,以便从指定路径中导入 Excel, txt, dta 等格式的数据文件,进而进行统计和回归分析,并最终将输出的图形、表格等结果保存到指定文件夹中,以便随后插入 Word, TeX 等写作文档中。
2.2 Stata 安装路径和个人文件夹的设置
安装 Stata 时,文件路径中尽量不要包含中文、空格和特殊字符。否则,会导致涉及读写或保存文档的程序无法运行。我个人通常将 Stata 安装在 D 盘根目录下,如 D:/stata17。
我会在 D 盘中另外建立一个文件夹 D:/stata,其中,
- 新建 personal 文件夹,用以保存我自己的数据和程序文件;
- 新建 plus 文件夹,用以存放外部命令。
这样做的好处是,无论 Stata 更新到哪个版本,我个人的文件都不会受到任何影响。例如,更新到 Stata 18 后,我只需将 D:/stata17/profile.do 文档复制到 D:/stata18 目录下即可。
Stata 17 目录下的文档结构
Stata 安装目录 D:/stata17/ 的文档结构如下:
D:/stata17::
--- 解释 ---
├── ado
│ └── base | Stata 官方提供的程序文件(按 _, A-Z 分类)
├── docs | Stata 电子手册(PDF 格式),便于查阅
└── utilities | 包含 JAVA、Python 等插件和工具
│ profile.do | Stata 启动时自动执行该文件中的命令
│ mp-64.dll | Stata 运行所需的动态链接库文件
│ STATA.LIC | Stata 的许可证文件,用于验证软件合法性
│ StataMP-64.exe | Stata 的主执行文件,用于启动程序
│ StataMP-64_old.exe | 旧版本的 Stata 执行文件(备份或兼容用途)说明如下:
- 不要随意修改
ado/base目录中的文件,以免影响 Stata 的正常运行。 - 可以通过编辑
profile.do文件来定制 Stata 的启动行为,例如设置工作目录或加载常用脚本。后文会详细介绍。 - 如果需要使用插件或外部工具,可以将相关文件放置在
utilities目录中,确保路径正确。我们通常无需自行设定,再安装或关联外部插件时,Stata 会自动将相关文件存入此处。
个人文件夹的文档结构
存放我个人文档的目录 D:/stata/ 的结构如下:
D:/stata::
--- 解释 ---
├── personal | 存放个人文档 (数据, dofiles 等)
│ ├── data
│ ├── paper
│ └── ...
├── do | 存放自动生成的日志文件
└── plus | 存放外部命令说明如下:
- personal 目录下可以根据需要设定多个子文件夹,用于分类存储不同项目的文件。基本原则是,一个项目一个文件夹。
- do 目录用于存放自动生成的日志文件 (log 文件),记录 Stata 运行过程中的命令和输出结果,复现分析过程或排查问题。随后在 profile 文档 部分会有详细介绍。
- plus 目录用于存放通过
net install或ssc install等命令安装的外部命令 (ado 文件)。
当然,你也可以酌情添加其他文件夹。
2.3 工作路径 (Working Directory)
在 Stata 主界面的右下角会显示当前 工作路径/目录(Working Directory),是 Stata 默认的文件读取和保存位置。比如,执行 use mydata.dta 时,默认从当前工作目录下读取 mydata.dta 数据文件 (如果该目录下未保存 mydata.dta 文件,则 Stata 会报错);执行 save newdata.dta, replace 时,newdata 文件会自动保存到当前工作目录下。
要在结果窗口中显示当前工作路径,可以执行 cd 或 pwd 命令。若需切换工作路径,只需在 cd (_c_hange _d_irectory) 命令后写上新的工作路径名称即可,例如 cd "D:/Projects/SJ_paper" (注意:必须是已经存在的文件夹路径)。合理设置工作目录不仅能减少重复输入路径的麻烦,还能让文件管理更加清晰高效,是 Stata 使用中的一项基础但重要的操作。
2.4 profile 文档:开机自动执行的命令
每次启动 Stata 时,他都会到安装目录下查找是否存在名为 profile.do 的 dofile,若有则自动执行该文档中的所有命令 (即,do profile.do)。因此,你可以把一些常规的设定都放在 profile.do 中,比如,plus 文件夹的默认路径,personal 文件夹的路径、显示格式等。
创建和修改 profile.do
Step 1: 查看系统路径。输入 sysdir 命令,确认 Stata 的安装路径 (因人而异):
. sysdir
STATA: D:/stata17 // !! Stata安装根目录
BASE: D:/stata17/ado/base // 官方命令都存放于此
SITE: D:/stata17/ado/site // 可以忽略
PLUS: D:/stata/plus // (可能没有)
PERSONAL: D:/stata/personal // (可能没有)Step 2: 创建 profile.do 文档。在 Stata 命令窗口输入如下命令,以便在 Stata 安装目录 下新建一个名为 profile.do 的 dofile:
doedit "D:/stata17/profile.do"执行后,会弹出一个空白的 dofile。
Note: 如果执行上述命令后弹出的 profile.do 文档中已经有内容了,则表明你的系统中已经设定了 profile.do 文档,你只需要酌情修改即可。
Step 3: 设定 profile.do 中的内容 → 保存。如下是一个最基本的 profile.do:
*-文件路径设定:外部命令的存放位置
global path "D:/stata" // 个人路径,酌情修改
sysdir set PLUS `"$path/plus"' // 外部命令的存放位置
sysdir set PERSONAL `"$path/personal"' // 个人文件夹位置我们使用 sysdir set 命令指定了 plus 和 personal 文件夹的位置。需要说明的是,global path "D:/stata" 中需要填入你的个人文件夹所在位置,并在该文件夹下预先新建名为 plus 和 personal 的文件夹。
Step 4: 查验。重启 Stata,结果窗口应该显示如下信息:
Running D:/stata17/profile.do ...你还可以做如下测试:
测试 1:在命令窗口中输入
sysdir,显示的信息应该与 Step 1 相同。测试 2:在命令窗口中输入
ssc install jwdid, replace,安装外部命令jwdid,结果窗口会显示信息如下:. ssc install jwdid checking jwdid consistency and verifying not already installed... installing into D:/stata/plus\... installation complete.
可以看到,jwdid 的相关程序文件被正确安装到 Step 3 中设定的 plus 文件夹中。
Step 5: 添加更多的设定。如下是我正在使用的 profile.do 文档,你可以根据自己的需要酌情修改。每次修改完毕后,可以重启 Stata,并按照 Step 4 中介绍的方法进行查验。
*----------------------- profile.do ------------A Sample--
*-基本设定
set update_query off // 不要自动更新
set more off, perma // 不显示 -more- 分页提示信息
*-文件路径设定:外部命令的存放位置, 参见 help set
global path "D:/stata" // 统一存放地址
sysdir set PLUS `"$path/plus"' // 外部命令的存放位置
sysdir set PERSONAL `"$path/personal"' // 个人文件夹位置
cd `"$path/personal"' // 默认工作路径
*-结果显示格式
set cformat %4.3f //回归结果中系数的显示格式
set pformat %4.3f //回归结果中 p 值的显示格式
set sformat %4.2f //回归结果中 se值的显示格式
*-log 文件:自动以当前日期为名存放于 stata/do 文件夹下
* 若 D:/stata/ 下没有 do 文件夹,则本程序会自动建立一个
cap cd `"$path/do"'
if _rc{
mkdir `"$path/do"' //检测后发现无 do 文件夹,则自行建立一个
}
cap log close
cap cmdlog close
local fn = subinstr("`c(current_time)'",":","-",2)
local fn1 = subinstr("`c(current_date)'"," ","",3)
log using $path/do/log-`fn1'-`fn'.log, text replace
cmdlog using $path/do/cmd-`fn1'-`fn'.log, replace
*---------------------- profile.do ----------------------我在码云仓库中放置了两份 profile 文档:简化版本;完整版本。
如果想在 profile.do 中添加更多的设置,可以输入 set 命令查看 Stata 的系统参数设定 ([R] set),也可以输入 cret list 查看你电脑中当前的参数设定。
其它参考资料
- 连玉君, 2020, 聊聊Stata中的profile文件
- 连玉君, 2021, 聊聊Stata中的profile文件-第二季
- Stata profile.do: nice tips
- The profile and sysprofile Do-Files
- Wernow, J.B., StataCorp, How can I automatically execute certain commands every time I start Stata?
- Statalist, 2017, profile.do - useful startups?
- STATA ON A MAC: Setting up a profile.do file,针对苹果用户。
2.5 Stata:执行命令和工作机制
我们可以才用过三种方式与 Stata 互动:
- 点击菜单 (新手适用,老手偶尔为之)
- 命令窗口 (简单的测试性任务)
- dofile (主要方式)

2.5.1 机制 1:把数据和程序拖入内存中
初学者很怕见到 clear 命令。事实上,如果你了解 Stata 的运行机制,就会明白,clear 是一个非常安全的命令。具体说明如下:
启动 Stata 时,电脑会分配给 Stata 一块 内存空间 (一座大房子)。解读如下:
- 当我们执行
use D:/myData/auto.dta命令时,Stata 会把存储于 D:/myData 文件夹中的auto.dta文件复制 (copy) 一份,读入内存。随后,执行sum,reg等命令时,Stata 都是从内存中读取这个副本数据,而无需再访问硬盘中的数据文件,即D:/myData/auto.dta。这样的好处是,可以大幅提高运算速度。缺陷在于,但计算机可以分配给 Stata 的内存空间有限时,Stata 会因为无法读入大文件,或运行中出现卡顿现象。 - Stata 执行程序时也采用了上述逻辑。当我们执行
tabstat var1时,Stata 会先到 D:/stata17/base/t/ 文件夹下找到名为tabstat.ado的程序文件,进而将其读入内存中再执行。当我们再次执行tabstat var2时,Stata 会直接从内存中执行tabstat.ado副本,而无需再访问硬盘的原始程序文件,即 D:/stata17/base/t/tabstat.ado。
Stata 会把「大房子」分成若干个小房间,分类存储 Data, Matrix, 返回值, 程序 等对象。若想清空某个「小房间」,可以使用 clear 房间类型 命令,例如:
clear:清空内存中的数据 (分配给 Stata 的内存中的 【Data】 那一块空间)clear matrix:清空内存中的矩阵对象clear results:清空内存中的返回值,如r(mean),r(N),e(r2)等clear all:清空分配给 Stata 的所有内存空间
![]()
有关 clear 命令的详情,请参阅 help clear,或 [D] clear。
作为例子,我们来解释一下如下命令的的含义:
use "D:/myData/auto.dta", clear上述命令等价于:
clear
use "D:/myData/auto.dta"也就说,虽然 clear 选项置于命令的末尾,但却是最先被执行的,它会清空内存中已有的数据文件。然后,Stata 从硬盘 (D:/myData/) 中拷贝 auto.dta 文件,并将该副本读入内存。
2.5.2 机制 2:结果呈现和输出
当我们按下图的方式执行 sum price 命令后,Stata 会同时以两种方式输出结果:
- 方式 1:将部分结果直接呈现于 结果窗口,通常会以特定的格式排列,可读性强。
- 方式 2:所有计算结果都会存入 内存 (按类别存入不同的 房间)。
- 这些结果统称为返回值 (return values)。对于
sum,tabstat等命令,可以使用return list命令显示之;对于regress,logit,xtreg等回归类命令,可以使用ereturn list命令显示之。 - 这些结果可以被后续代码调用,如
gen x_mean = r(mean) - 也可以借助
esttab,outreg2,reg2docx等命令调用后,输出到 Word 等文档中。
- 这些结果统称为返回值 (return values)。对于
![]()
简言之,你在 Stata 结果窗口中看到的只是一部分结果,这些结果以及其他相关结果都会被分门别类地存储在内存中,以便其他程序调用。如此以来,我们就可以让多个程序合作,采用「接力」的方式完成复杂的分析任务。
3. Dofile 编辑器
Stata 有三种命令执行方式,对比如下:
- 点击菜单:直观,但效率低,可重复性差,不推荐
- 命令窗口:适合一些简短的,测试性的命令
- dofile:也叫 do文档,适合记录复杂的分析过程,Stata 的程序 (ado) 文件也是在 dofile 编辑器中编写的;便于保存和重复操作,便于分享
任何一个好的研究项目的必备特征就是具有好的重复性,而借助 Do-file 可以轻松地实现结果的可重复性。下面介绍如何使用 Do-file。本节内容主要源于如下推文 (. lianxh dofile do文档):
- 张晓明, 2020, Stata中Dofile编辑器的使用.
- 吴芳倩, 2021, Stata:dofile模板DIY-速来认领吧.
- 张家星, 2023, Stata:写个像样的dofile有哪些标准动作?.
- 连享会, 2020, Stata-dofile-转换-PDF-制作讲义方法.
- 连享会, 2020, Stata:私人定制-dofile-编辑器模板.md.
- 刘聪聪, 2020, Stata 中 dofile 编辑器的配置 —— 来个漂亮的编辑器

3.1 新建、保存和打开 dofile
A. 新建和保存 Do-file
方法 1:点击菜单。点击 Stata 主界面第二行倒数第六个按钮 (形似一个空白的记事本上有一支黄色铅笔)。

方法 2:使用 doedit 命令。在 Stata 命令窗口中输入 doedit 即可新建一个空白的 Do-file,默认名称为 Untitled.do。更好的处理方法是指定 dofile 的名称和存储路径,例如
- 输入
doedit myAER,则会在当前工作路径下自动创建一个名为myAER.do的 dofile。 - 输入
doedit D:/paper/myAER,则会在 D:/paper/ 路径下创建一个名为myAER.do的 dofile。

我们可以在 dofile 中输入 Stata 命令,随后点击 「保存」 按钮,将其存入指定路径即可。例如,我们可以把新建的 Do-file 保存在 D:/Stata_Ex 文件夹下,名称为 Ex01.do,则该文件的完整存储路径为 D:/Stata_Ex/Ex01.do。
注意:Stata 的 do文档 有自己专属的文件类型,后缀为 .do。因此,保存时,请不要更改其默认的文件类型:「Do-file (*.do)」。至于文件名,则没有特殊要求,中英文均可。
B. 打开 dofile
有两种方式可以打开电脑上已经存在的 dofile:命令行方式和菜单方式。
命令行方式
刚才我们新建的 Do-file 的完整存储路径为 D:/Stata_Ex/Ex01.do,因此,我们只需在 Stata 命令窗口中输入如下命令即可打开之 (当文件路径包含空格时,请务必附加半角模式下的双引号):
. doedit "D:/Stata_Ex/Ex01.do"菜单方式
只需单击 Do-file 编辑器中的 「文件夹」按钮,定位至 Do-file 所在文件夹,找到需要打开的 Do-file 后,双击之即可打开。

3.3 dofile 的编写
如果你已经尝试过在命令窗口执行命令,那么,dofile 无非是将这些命令统一记录在一个文档中,以便后需修改和反复执行。
下面就是一个简单的 dofile:
*------------------------sample01.do ----
sysuse "auto.dta", clear
summarize price weight mpg
scatter mpg weight
reg mpg weight foreign
esttab, nogap
*------------------------sample01.do ----在上述代码中,我们按照以下步骤逐步完成分析:
- 加载数据:使用
sysuse命令加载 Stata 自带的auto.dta数据集。 - 描述性统计:使用
summarize命令对变量price、weight和mpg进行描述性统计,了解数据的基本特征。
- 可视化分析:使用
scatter命令绘制mpg与weight的散点图,直观展示两者之间的关系。
- 回归分析:使用
reg命令以mpg为因变量,weight和foreign为自变量进行回归分析,探究变量之间的统计关系。
- 结果输出:使用
esttab命令将回归结果以简洁的表格形式输出,便于进一步解读和报告。
通过将上述步骤整合到 dofile 中,不仅提高了代码的可重复性,还使得分析过程更加清晰和高效。
3.4 dofile 的执行
你可以执行 dofile 中的部分代码,也可以一次性执行所有代码。你甚至可以在一个 dofile 中执行另一个 dofile 中的所有代码。
局部执行:
多数情况下,我们只需要执行 dofile 中的部分命令。做法很简单:选中目标代码,点击下图所示按钮按钮;或按下快捷键 Ctrl+D

需要说明的是,你只需要选中某行中的一个以上的字符 (包括空格),Stata 就会执行该行的代码 (这与 R 不同)。
全部执行:
若不选中任何代码块,而直接按快捷键 Ctrl+D,则 Stata 会一次性你执行 dofile 中的所有代码。
有时候,这种操作可能不是你的本意,而是误操作,此时你可以点击 Stata 主界面中的红色叉号 (第二行最后一个按钮),即可强制中断执行过程。
使用命令:
我们也可以通过命令来执行整份 dofile:
do "D:/stata/personal/paper01/sample01.do"这种方式主要用于大型项目。例如,对于复杂的项目,我们可以将不同的处理任务写在不同的 dofile 中,并将这些 dofile 统一放置在 ../codes 文件夹中。然后,可以在项目的根目录下设定一个名为 master.do 的主文档。这有几个好处:其一,整个项目的文档结构非常清楚;其二,我们可以单独执行某一部分,也可以执行 master.do 中的所有命令,以便运行项目中涉及的所有代码。
*------------------------ master.do ------begin---
global path "D:/stata/personal/paper01"
cd "$path/codes"
do "01_data_clean.do"
do "02_summarize.do"
do "03_regression.do"
do "04_graph.do"
*------------------------ master.do ------over----3.5 添加注释语句
为了增加 dofile 的可读性,我们需要添加一些注释语句,主要包括:
- 列明文档的标题、作者、生成日期等
- 添加一些大标题,以便使文档结构清晰
- 解释关键语句的目的和作用
Stata 中有三种添加注释语句的方法:
- 单行注释: 在行首使用
*号,则该行内容会被自动忽略。一次只能注释一行语句。 - 行尾注释: 在一行命令之后至少加一个空格再加
//字符,该行命令中//后的内容将被视为注释而忽略。快捷键:选中需要注释的语句,按Ctrl + /。 - 多行注释: 将需要注释的内容放在
/* */组合字符里边,被该组字符括起来的内容会被忽略。快捷键:选中需要注释的语句,按Ctrl + Shift + /。
3.6 断行:三种方法
当所使用的命令很长需要换行的时候,可以使用以下三种方法来实现对命令的分行操作,从而实现分行后的命令承接上一行的操作:
- M1. 配合使用
#delimit ;和#delimit cr。使用#delimit ;命令,可以将换符设置为;(Stata 的默认换行符是回车键);使用#delimit cr命令用来恢复默认换行符。 - M2. 使用字符组合
///来实现上下行的连接。 - M3. 用注释符
/* */来连接上下行,在操作过程中只需将上下行使用注释字符连接起来即可。
下面是一些典型的例子:

3.7 dofile 编辑器的美化和语法高亮
在 dofile 编辑器中,依次点击:编辑 → 首选项,可以在 常规、颜色、自动完成 等子选项卡中对 dofile 编辑器的配色、字体等进行个性化设定。
注意:完成本节介绍的各项设定后,可以参照 1.5 小节的方法保存为模板。
详情参见 help dofile,[U] 16 Do-files,以及如下推文:
- 刘聪聪, 2020, Stata 中 dofile 编辑器的配置 —— 来个漂亮的编辑器.
- 连享会, 2020, Stata:私人定制-dofile-编辑器模板.md.
常规-选项卡:字体、字号、缩进等
- 依次点击:编辑 → 首选项 → 常规

颜色-选项卡:语法高亮
- 依次点击:编辑 → 首选项 → 颜色 (Colors)。
- 可以根据自己的喜好设定各类元素的配色。

3.8 良好的代码写作习惯
为了满足可重复性研究的要求,我们的代码不但要能正确执行,还应该清晰、易读。如下是一些 基本建议:
- 所有的操作 (包括: 数据处理、绘图、回归分析、结果输出等) 都要记录在 dofile 中,尽量避免手动处理
- 每个项目 (每篇论文) 一个文件夹;文件分类存放,文件尽可能按照特定规则命名
- 工作中,实时保存的是 dofiles,而不是 数据文件
- 多加注释,以便增强代码的可读性
- 注意排版,保证美观的同时,也便于查错
这里,先提供一个虚构的「dofile 样本」,以便让各位了解上述原则的基本精神。
- 首先,在 dofile 的开头,标明了文件的生成日期、作者、作用等;
- 其次,在「A. 基本设定」部分用全局暂元
global定义了文件的存储路径和子文件夹的名称简写,以便后续将不同类新的文件分门别类地存放起来; - 再次,D#.xxx,S#.xxx,R#.xxx 等部分依次为数据处理、统计分析和回归分析等内容。如此以来,即使 dofile 写的很长,仍然可以通过 Ctrl+F 快捷键快速搜索关键词定位。
- 最后,值得注意是,我们频繁地使用了
local和global,尤其是【R. 回归分析】部分。这种做法好处很多,比如,代码的结构看起来很清晰;很容易修改,只需在定义暂元的地方统一做一次修改即可,这可以大幅降低出错的概率;代码变得很简洁,可读性自然就提高了。
*------------------
*- 一个 dofile 范本 www.lianxh.cn
*------------------
* Version 1.2, 2035/1/2
* Author: 连家大公子
* 目的:分析家庭收入对子女学习成绩的影响
*------------
*-A. 基本设定
global path "D:/myPaper/Income_Mark" //定义项目目录
// 需要预先在生成子文件夹:data, refs, out, adofiles
global D "$path/data" //数据文件
global R "$path/refs" //参考文献
global Out "$path/out" //结果:图形和表格
adopath + "$path/adofiles" //自编程序+外部命令
cd "$D" //设定当前工作路径
set scheme s2color
*-核心参考资料 (参考文献和文档都存放于 $R 文件夹下)
shellout "$R/Safin_Federer_2005_Aust.pdf"
*------------
*-D1. 数据导入
import excel using "$D/Income_Mark.xlsx", first clear
save "_temp_" // $D\ 可以省略,应为当前工作路径就是 $D
// 如果原始数据文件不大,此步骤可以省略
*------------
*-D2. 数据处理
gen ……
winsor2 ……
……
save "data_dealed.dta", replace
*----------------------
*-S1. 基本描述性统计分析
// 如果数据处理部分未作更新,可直接这里进行后续分析
*-----表x:基本统计量-------
use "data_dealed.dta", clear
local v " " //填入变量名
local s "$Out/Table1_sum" //存储的文件名(或路径\文件名)
logout, save("`s'") excel replace: ///
tabstat `v', stat(mean sd p50 min max) f(%6.2f) c(s)
*-----表x:相关系数矩阵-------
local v " " //填入变量名
local s "$Out/Table2_corr" //存储的文件名(或路径\文件名)
logout, save("`s'") excel replace: ///
pwcorr_a `v', format(%6.2f) //star(0.05)
*-----------------
*-S2. 分组统计分析
use "data_dealed.dta", clear
*-----表x:组间均值差异检验-------
local v " " //填入变量名
local s "$Out/ttable2" //存储的文件名(或路径\文件名)
logout, save("`s'") excel replace: ///
ttable2 `v', by(variable) format(%6.2f)
*-------------
*-R. 回归分析
use "data_dealed.dta", clear
global y "Mark" //被解释变量
global x "Income" //基本解释变量
global z "edu_Dad edu_Mum Age##Age ……" //基本控制变量
global w "i.year i.industry i.race" //虚拟变量
*global opt ", vce(robust)"
global opt ", vce(cluster industry)"
reg $y $x $opt
est store m1
reg $y $x $z $opt
est store m2
reg $y $x $z $w $opt
est store m3
*-----表x:回归结果-------
local s "using $Out/Table3_reg.csv" //执行时包括这一行会输出Excel表格
local m "m1 m2 m3"
esttab `m' `s', nogap compress replace ///
b(%6.3f) s(N r2_a) drop(`drop') ///
star(* 0.1 ** 0.05 *** 0.01) ///
addnotes("*** 1% ** 5% * 10%") ///
indicate("行业效应 =*.industry" "年度效应 =*.year")事实上,你若能在开始时遵守上述基本原则,就会慢慢发现它的好处远远大于你花费在排版上的成本。久而久之,你也会形成自己的代码风格。
下面,着重解释一些最重要的原则。
A. 实时保存 dofile 而不是数据文件
有些人在下班前喜欢把当天处理好的数据另存一份,这是个非常糟糕的习惯!
我的建议是:保存 dofile,而不是数据文件! 原因很简单,一个 dofile 只有几 k 或几十 k,但数据文件往往很大。如果保存了太多版本的数据文件,随后会导致严重的混乱,也就很难保证研究结果的可重复性。有些时候,数据处理环节比较复杂,代码运行时间也较长,可以保存 1-2 次过程数据,从而加快后续处理效率。要注意的是,在 dofile 中保存过程数据时,一定要添加注释语句,并将过程数据与原始数据存放到不同的文件夹中,以免混淆或误删。
B. 空格和注释语句
Stata没有空格和制表符的限制,为了让代码更加美观和易读,要合理使用空格和缩进。
rename k12_unique_id sid
rename class_unique_id class_id
rename teacher_name teacher
*或者这样
rename k12_unique_id sid
rename class_unique_id class_id
rename teacher_name teacher
//可以看到后者更直观。缩进对代码的跨行阅读也有帮助,在视觉上更容易接受:
// Good
keep sid class_id teacher grade1 ///
grade2 grade3 pass
// Bad
keep sid class_id teacher grade1 ///
grade2 grade3 pass3.8 文档结构
合理设置文档结构也是实现可重复研究的关键。请参阅如下推文:
- 邹恬华, 2022, Stata论文复现:做一个优雅的码农, 连享会 No.928.
- 张弛, 2024, Stata代码规范指南, 连享会 No.1452.
- 汪京, 2024, Stata代码规范指南, 连享会 No.1377. 秦范, 2022, Stata:论文重现代码模板, 连享会 No.882.
如下论文的复现文档都设置了非常严谨的文档结构,供参考:
- Ewens, M., Xiao, K., & Xu, T. (2024). Regulatory costs of being public: Evidence from bunching estimation. Journal of Financial Economics, 153, 103775. Link (rep), PDF, Google. -Appendix-, github-part-of-Data, -Replication-
- Nagengast, A. J., & Yotov, Y. V., 2025. “Staggered Difference-in-Differences in Gravity Settings: Revisiting the Effects of Trade Agreements.” American Economic Journal: Applied Economics, forthcoming. Link, PDF, -Appendix-, Google, -Replication-
- Barwick, Panle Jia, Shanjun Li, Liguo Lin, and Eric Yongchen Zou. 2024. "From Fog to Smog: The Value of Pollution Information." American Economic Review, 114 (5): 1338–81. DOI: 10.1257/aer.20200956 Link, PDF, -Replication-, -Appendix-, Google